About this deal
Vocab ¶ class torchtext.vocab. Vocab ( counter, max_size=None, min_freq=1, specials=['
Best Flashlight Gloves on the market in 2021 in the UK 10 Best Flashlight Gloves on the market in 2021 in the UK
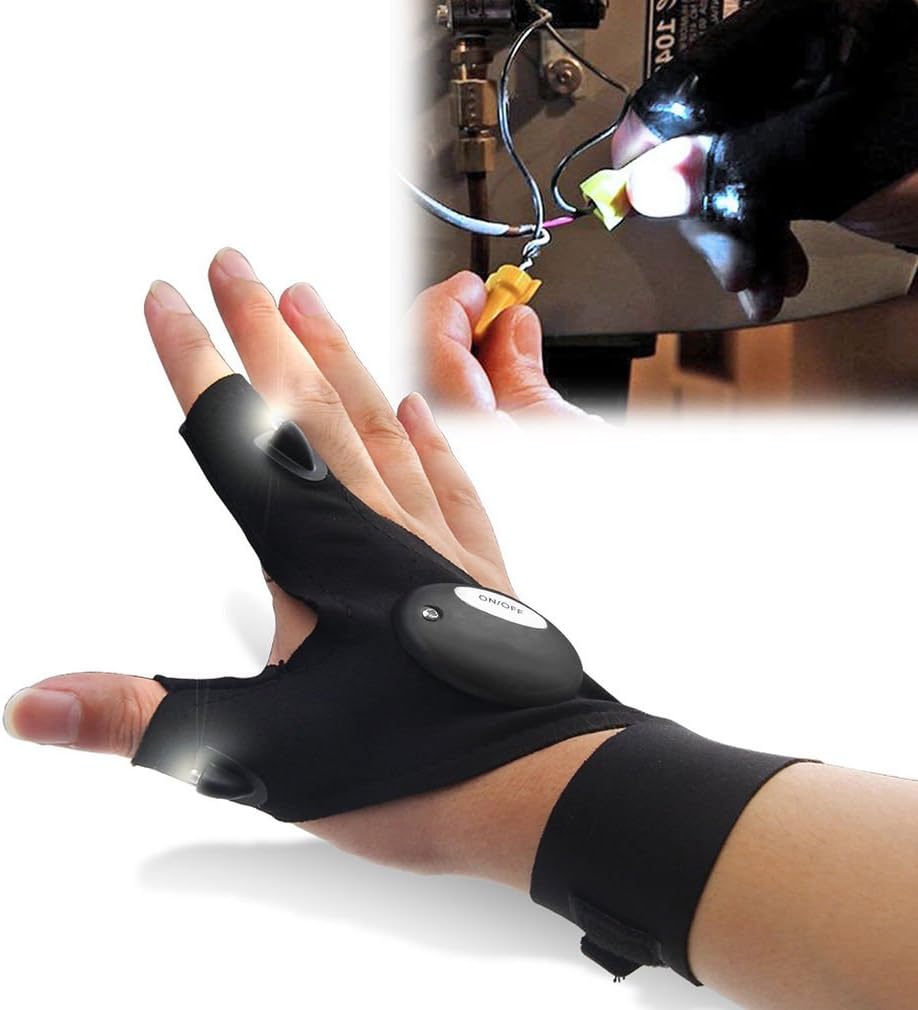
Vectors -> Indices def emb2indices(vec_seq, vecs): # vec_seq is size: [sequence, emb_length], vecs is size: [num_indices, emb_length] One surprising aspect of GloVe vectors is that the directions in the embedding space can be meaningful. The structure of the GloVe vectors certain analogy-like relationship like this tend to hold: We can likewise flip the analogy around: print_closest_words(glove['queen'] - glove['woman'] + glove['man']) RuntimeError – If an index within indices is not int range [0, itos.size()). set_default_index ( index : Optional [ int ] ) → None [source] ¶ Parameters :LONG WORKING HOURS & REPLACEABLE BATTERY ]- If you've been looking for led flashlight gloves that can stay working for a long time, this will be your best choice. because our led flashlight multipurpose gloves are powered by two button batteries and can stay lit for long enough time before you have to replace its battery. We can move an embedding towards the direction of "goodness" or "badness": print_closest_words(glove['programmer'] - glove['bad'] + glove['good']) As the earlier answer mentioned, you can pass the list of word strings(tokens) in via glove.stoi[word_str].
Garyesh Pack of Two Outdoor LED Glove Flashlight Torch Cover
word_indices = torch.argmin(torch.abs(vec_seq.unsqueeze(1).expand(vs_new_size)- vecs.unsqueeze(0).expand(vec_new_size)).sum(dim=2),dim=1) It is a torch tensor with dimension (50,). It is difficult to determine what each number in this embedding means, if anything. However, we know that there is structure in this embedding space. That is, distances in this embedding space is meaningful.Beyond the first result, none of the other words are even related to programming! In contrast, if we flip the gender terms, we get very different results: print_closest_words(glove['programmer'] - glove['woman'] + glove['man']) Easy to use] LED light gloves is with on and off button and 2 LED lamp beads, to make your work more convenient. Great for fishing lover, gadget lover, handyman, plumber, camping, and outdoor work, etc. can be used for many activities during night time or in the darkness such as car repairing, fishing, camping, hunting, patrol, cycling, emergency survival, etc. It's very handy when no one is there to hold the light for you.
GLOVE TORCH Flashlight LED torch Light Flashlight Tools
We could also look at which words are closest to the midpoints of two words: print_closest_words((glove['happy'] + glove['sad']) / 2) path_pretraind_model='./GoogleNews-vectors-negative300.bin/GoogleNews-vectors-negative300.bin' #set as the path of pretraind model The PyTorch function torch.norm computes the 2-norm of a vector for us, so we can compute the Euclidean distance between two vectors like this: x = glove['cat'] After having built the vocabulary with its embeddings, the input sequences will be given in the tokenised version where each token is represented by its index. In the model you want to use the embedding of these, so you need to create the embedding layer, but with the embeddings of your vocabulary. The easiest and recommended way is nn.Embedding.from_pretrained, which is essentially the same as the Keras version. embedding_layer = nn.Embedding.from_pretrained(TEXT.vocab.vectors)Let's use GloVe vectors to find the answer to the above analogy: print_closest_words(glove['doctor'] - glove['man'] + glove['woman']) Silicone Button - LED light set in the head of thumb and index finger that covered by silicone, effective prevent water ingress when fishing or rain. These fishing gloves use 2 x CR2016 button batteries that can be replaced easily by loosen the screw with a screwdriver. Now that we have a notion of distance in our embedding space, we can talk about words that are "close" to each other in the embedding space. For now, let's use Euclidean distances to look at how close various words are to the word "cat". word = 'cat' The word_to_index and max_index reflect the information from your vocabulary, with word_to_index mapping each word to a unique index from 0..max_index (not that I’ve written it, you probably don’t need max_index as an extra parameter). I use my own implementation of a vectorizer, but torchtext should give you similar information. We see similar types of gender bias with other professions. print_closest_words(glove['programmer'] - glove['man'] + glove['woman'])
Glove Torch - Etsy UK
I thought the Field function build_vocab() just builds its vocabulary from the training data. How are the GloVe embeddings involved here during this step? RuntimeError – If token already exists in the vocab forward ( tokens : List [ str ] ) → List [ int ] [source] ¶ If it helps, you can have a look at my code for that. You only need the create_embedding_matrix method – load_glove and generate_embedding_matrix were my initial solution, but there’s not need to load and store all word embeddings, since you need only those that match your vocabulary. RuntimeError – If index is not in range [0, Vocab.size()] or if token already exists in the vocab. lookup_indices ( tokens : List [ str ] ) → List [ int ] [source] ¶ Parameters : HANDY & CONVENIENT ]- Humanized hands-free lighting design, fingerless glove with 2 led lights on index finger and thumb. no more struggling in the darkness to find lighting or getting frustrated holding a flashlight while work on something that requires both hands.I'm coming from Keras to PyTorch. I would like to create a PyTorch Embedding layer (a matrix of size V x D, where V is over vocabulary word indices and D is the embedding vector dimension) with GloVe vectors but am confused by the needed steps. torchtext.vocab ¶ Vocab ¶ class torchtext.vocab. Vocab ( vocab ) [source] ¶ __contains__ ( token : str ) → bool [source] ¶ Parameters :
 Great Deal
Great Deal